- Mahuri Tummalapalli, Manoj Chinnakotla, Radhika Mamidi

I would like to present summary of couple of Natural Language processing research done at International Institute of Information Technology IIIT Hyderabad in this and upcoming blog posts.
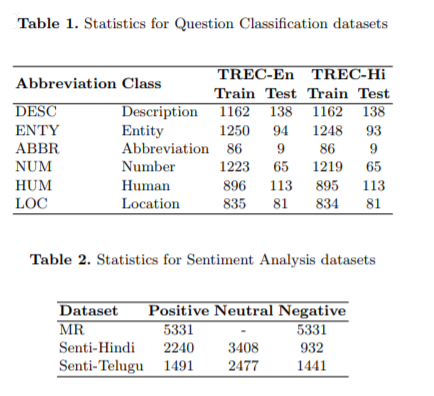
English Sentence classification methods highly dependent on language resources that does parsing or relay on labeled and un labeled data, That makes difficult to adapt them to other languages. Paper evaluates on deep learning techniques for sentence classification on morphological rich Indian languages, Particularly on Hindi and Telugu.
Author took Hindi annotated data by translating the TREC-UIUC data-set. Author shed light on multiInput-CNN variant and is able to perform better
Morphological Rich and Agglutinating means...?
A Morphological Rich Languages (MRL) is one which grammatical relations like Subject, Predicate, Object, etc., are indicated by changes to the words instead of relative position or addition of particles.

An Agglutinative language is a type of synthetic language with morphology that primarily uses agglutination. Words may contain different morphemes to determine their meanings, but all of these morphemes (including stems and affixes) remain, in every aspect, unchanged after their unions.
Paper does two tasks with the translated Hindi and Telugu data-sets.
Question Classification
Author uses Bag of words, WH-Word in Question, Word Shape, Question length, etc WH-Words are extracted using Rules on Parse trees.
He also uses Hypernyms(named entities) and named entities.
Sentiment Analysis
Sentiment Analysis uses Bag of Words for features extraction (unigram, Bigram).
Parts of Speech (POS) tags, adjectives,etc.
Models
High light of the paper that attracted me is Context Vectors.- Dynamic CNN - Dynamic k means pooling was introduced. A dynamic k-max pooling operations is where the k is deciding function of length of the sentence and the death of the network.
- LSTM - is used to retain dependency sensitive model and then apply output to a CNN get final result. These are called Context Vectors (CoV)
- Context Vector -A context vector is associated with every unique word in the training corpus. A self organization-based learning approach is used to derive these context vectors such that vectors for words that are used in similar contexts will point in similar directions.
- Attention mechanism in multiInput-CNN
What is AttentionBasic model proposed by Kim for Attension model for more details ref
Attention Mechanism can be viewed as a method for making the RNN work better by letting the network know where to look as it is performing its task. Ref for more on attention
Author customised Attention based multiInput -CNN to gain performance
- SVM
The SVM is trained with a linear kernel on bag-of-words, bag-of-word ngrams and bag-of-character ngram input. Author fed a combination of word and character ngrams to the SVM for experiments.
Experiments and results
The experiments have been divided into three parts. Table 3 below presents detailed evaluation and discussion of different baseline models and inputs on all data-sets. Table 4 compares multiInput-CNN model’s performance with the baselines and other state-of-the arts. In Table 5, Author tries to understand the inherent data-set biases across languages.


Author proposes Future research on experiments on the topic can be referred in paper.
Comments