-By
Raghavendra Chalapathy
University of Sydney,
Capital Markets Co-operative Research Centre (CMCRC)
Sanjay Chawla
Qatar Computing Research Institute (QCRI),
HBKU
Anomaly detection also known as outlier detection is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data. Typically the anomalous items will translate to some kind of problem such as bank fraud, a structural defect, medical problems or errors in a text. Anomalies are also referred to as outliers, novelties, noise, deviations and exceptions
Hawkins defines an outlier as an observation that deviates so significantly from other observations as to arouse suspicion that it was generated by a different mechanism.

Aim of this paper is two-fold, First is a structured and comprehensive overview of research methods in deep learning-based anomaly detection. Furthermore the adoption of these methods for anomaly across various application domains and assess their effectiveness.
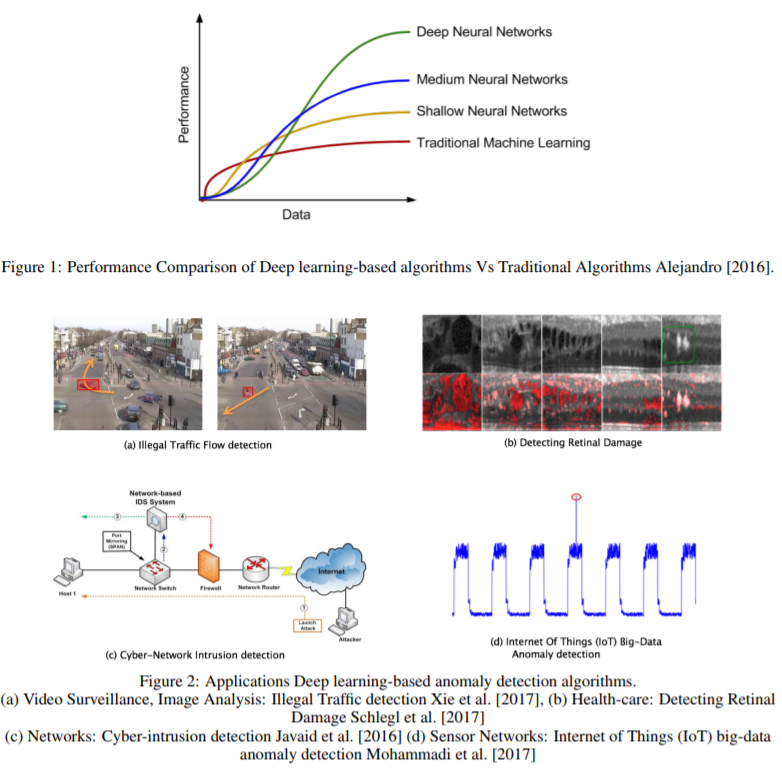
The performance of different methods depends a lot on the data set and parameters, and methods have little systematic advantages over another when compared across many data sets and parameters
Key Components associated with deep learning-based anomaly detection technique
Key Components associated with deep learning-based anomaly detection technique

Type of Anomaly
Anomalies can be broadly classified into three types: point anomalies, contextual anomalies and collective anomalies. Deep anomaly detection (DAD) methods have been shown to detect all three types of anomalies with great success.
Point Anomalies
The majority of work in literature focuses on point anomalies. Point anomalies often represent an irregularity or deviation that happens randomly and may have no particular interpretation. For instance, in Figure 10 a credit card transaction with high expenditure recorded at Monaco restaurant seems a point anomaly since it significantly deviates from the rest of the transactions.
Contextual Anomaly Detection
A contextual anomaly is also known as the conditional anomaly is a data instance that could be considered as anomalous in some specific context. Contextual anomaly is identified by considering both contextual and behavioural features. The contextual features, normally used are time and space. While the behavioral features may be a pattern of spending money, the occurrence of system log events or any feature used to describe the normal behavior. Figure 9a illustrates the example of a contextual anomaly considering temperature data indicated by a drastic drop just before June; this value is not indicative of a normal value found during this time. Figure 9b illustrates using deep Long Short-Term Memory (LSTM) based model to identify anomalous system log events in a given context (e.g event 53 is detected as being out of context).

Collective or Group Anomaly Detection.
Anomalous collections of individual data points are known as collective or group anomalies, wherein each of the individual points in isolation appears as normal data instances while observed in a group exhibit unusual characteristics. For example, consider an illustration of a fraudulent credit card transaction, in the log data shown in Figure 10, if a single transaction of ”MISC” would have occurred, it might probably not seem as anomalous. The following group of transactions of valued at $75 certainly seems to be a candidate for collective or group anomaly. Group anomaly detection (GAD) with an emphasis on irregular group distributions (e.g., irregular mixtures of image pixels are detected using a variant of autoencoder model.

Several anomaly detection techniques have been proposed in literature. Some of the popular techniques are:
- Density-based techniques (k-nearest neighbor, local outlier factor, isolation forests, and many more variations of this concept).
- Subspace-, correlation-based and tensor-based outlier detection for high-dimensional data.
- One-class support vector machines.
- Replicator neural networks.
- Bayesian Networks.
- Hidden Markov models (HMMs).
- Cluster analysis-based outlier detection.
- Deviations from association rules and frequent itemsets.
- Fuzzy logic-based outlier detection.
- Ensemble techniques, using feature bagging, score normalization and different sources of diversity.
There are many Deep Anomaly Detection applications out there among them i would like to highlight Intrusion Detection and Log Analysis Detection.
The intrusion detection system (IDS) refers to identifying malicious activity in a computer-related system. IDS may be deployed at single computers known as Host Intrusion Detection (HIDS) to large networks Network Intrusion Detection (NIDS). The classification of deep anomaly detection techniques for intrusion detection is in Figure 11. IDS depending on detection method are classified into signature-based or anomaly based. Using signature-based IDS is not efficient to detect new attacks, for which no specific signature pattern is available, hence anomaly based detection methods are more popular.

Host-Based Intrusion Detection Systems (HIDS):
Such systems are installed software programs which monitors a single host or computer for malicious activity or policy violations by listening to system calls or events occurring within that host. The system call logs could be generated by programs or by user interaction resulting in logs. Malicious interactions lead to the execution of these system calls in different sequences. HIDS may also monitor the state of a system, its stored information, in Random Access Memory (RAM), in the file system, log files or elsewhere for a valid sequence. Deep anomaly detection (DAD) techniques applied for HIDS are required to handle the variable length and sequential nature of data. The DAD techniques have to either model the sequence data or compute the similarity between sequences.Network Intrusion Detection Systems (NIDS):
NIDS systems deal with monitoring the entire network for suspicious traffic by examining each and every network packet. Owing to real-time streaming behavior, the nature of data is synonymous to big data with high volume, velocity, variety. The network data also has a temporal aspect associated with it. A challenge faced by DAD techniques in intrusion detection is that the nature of anomalies keeps changing over time as the intruders adapt their network attacks to evade the existing intrusion detection solutions.Log Anomaly Detection
Anomaly detection in log file aims to find text, which can indicate the reasons and the nature of the failure of a system. Most commonly, a domain-specific regular-expression is constructed from past experience which finds new faults by pattern matching. The limitation of such approaches is that newer messages of failures are easily are not detected. The unstructured and diversity in both format and semantics of log data pose significant challenges to log anomaly detection. Anomaly detection techniques should adapt to the concurrent set of log data generated and detect outliers in real time. Following the success of deep neural networks in real time text analysis, several DAD techniques illustrated in Table 13 model the log data as a natural language sequence are shown very effective in detecting outliers
Challenges in Deep anomaly detection (DAD) techniques
• Performance of traditional algorithms in detecting outliers is sub-optimal on the image (e.g. medical images) and sequence datasets since it fails to capture complex structures in the data.
• Need for large-scale anomaly detection: As the volume of data increases let’s say to gigabytes then, it becomes nearly impossible for the traditional methods to scale to such large scale data to find outliers.
• Deep anomaly detection (DAD) techniques learn hierarchical discriminate features from data. This automatic feature learning capability eliminates the need of developing manual features by domain experts, therefore advocates to solve the problem end-to-end taking raw input data in domains such as text and speech recognition.
• The boundary between normal and anomalous (erroneous) behavior is often not precisely defined in several data domains and is continually evolving. This lack of well-defined representative normal boundary poses challenges for both conventional and deep learning-based algorithms.
Deep neural network architectures for locating anomalies
Deep Neural Networks (DNN)
The ”deep” in ”deep neural networks” refers to the number of layers through which the features of data are extracted. Deep architectures overcome the limitations of traditional machine learning approaches of scalability, and generalization to new variations within data and the need for manual feature engineering. Deep Belief Networks (DBNs) are class of deep neural network which comprises multiple layers of graphical models known as Restricted Boltzmann Machine (RBMs). The hypothesis in using DBNs for anomaly detection is that RBMs are used as a directed encoder-decoder network with backpropagation algorithm. DBNs fail to capture the characteristic variations of anomalous samples, resulting in high reconstruction error. DBNs are shown to scale efficiently to big-data and improve interpretability.Spatio Temporal Networks (STN)
Researchers for long have explored techniques to learn both spatial and temporal relation features. Deep learning architectures is leveraged to perform well at learning spatial aspects ( using CNN’s) and temporal features ( using LSTMs) individually. Spatio Temporal Networks (STNs) comprises of deep neural architectures combining both CNN’s and LSTMs to extract spatiotemporal features. The temporal features (modeling correlations between near time points via LSTM), spatial features (modeling local spatial correlation via local CNN’s) are shown to be effective in detecting outliers.Sum-Product Networks (SPN)
Sum-Product Networks (SPNs) are directed acyclic graphs with variables as leaves, and the internal nodes, and weighted edges constitute the sums and products. SPNs are considered as a combination of mixture models which have fast exact probabilistic inference over many layers. The main advantage of SPNs is that, unlike graphical models, SPNs are more traceable over high treewidth models without requiring approximate inference. Furthermore, SPNs are shown to capture uncertainty over their inputs in a convincing manner, yielding robust anomaly detection. SPNs are shown to be impressive results on numerous datasets, while much remains to be further explored in relation to outlier detection.Word2vec Models
Word2vec is a group of deep neural network models used to produce word embeddings. These models are capable of capturing sequential relationships within data instance such as sentences, time sequence data. Obtaining word embedding features as inputs are shown to improve the performance in several deep learning architectures. Anomaly detection models leveraging the word2vec embeddings are shown to significantly improve performance.Generative Models
Generative models aim to learn exact data distribution in order to generate new data points with some variations. The two most common and efficient generative approaches are Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN). A variant of GAN architecture known as Adversarial autoencoders (AAE) that use adversarial training to impose an arbitrary prior on the latent code learned within hidden layers of autoencoder are also shown to learn the input distribution effectively. Leveraging this ability of learning input distributions, several Generative Adversarial Networks-based Anomaly Detection (GAN-AD) frameworks proposed are shown to be effective in identifying anomalies on high dimensional and complex datasets. However traditional methods such as K-nearest neighbors (KNN) are shown to perform better in scenarios which have a lesser number of anomalies when compared to deep generative models. ´Convolutional Neural Networks
Convolutional Neural Networks (CNN), are the popular choice of neural networks for analyzing visual imagery. CNN’s ability to extract complex hidden features from high dimensional data with complex structure has enabled its use as feature extractors in outlier detection for both sequential and image dataset. Evaluation of CNN’s based frameworks for anomaly detection is currently still an active area of research.Sequence Models
Recurrent Neural Networks (RNNs) are shown to capture features of time sequence data. The limitations with RNNs is that they fail to capture the context as time steps increases, in order to resolve this problem, Long Short-Term Memory networks were introduced, they are a particular type of RNNs comprising of a memory cell that can store information about previous time steps. Gated Recurrent Unit (GRU) are similar to LSTMs, but use a set of gates to control the flow of information, instead of separate memory cells. Anomaly detection in sequential data has attracted significant interest in the literature due to its applications in a wide range of engineering problems Long Short Term Memory (LSTM) neural network based algorithms for anomaly detection have been investigated and reported to produce significant performance gains over conventional methods.Autoencoders
Autoencoders with single layer along with a linear activation function are nearly equivalent to Principal Component Analysis (PCA). While PCA is restricted to a linear dimensionality reduction, auto encoders enable both linear or nonlinear transformations. One of the popular applications of Autoencoders is anomaly detection. Autoencoders are also referenced by the name Replicator Neural Networks (RNN). Autoencoders represent data within multiple hidden layers by reconstructing the input data, effectively learning an identity function. The autoencoders, when trained solely on normal data instances ( which are the majority in anomaly detection tasks), fail to reconstruct the anomalous data samples, therefore, producing a large reconstruction error. The data samples which produce high residual errors are considered outliers. Several variants of autoencoder architectures are proposed as illustrated in Figure 13 produce promising results in anomaly detection. The choice of autoencoder architecture depends on the nature of data, convolution networks are preferred for image datasets while Long short-term memory (LSTM) based models tend to produce good results for sequential data. Efforts to combine both convolution and LSTM layers where the encoder is a convolutional neural network (CNN) and decoder is a multilayer LSTM network to reconstruct input images are shown to be effective in detecting anomalies within data. The use of combined models such as Gated recurrent unit autoencoders (GRU-AE), Convolutional neural networks autoencoders (CNN-AE), Long short-term memory (LSTM) autoencoder (LSTM-AE) eliminates the need for preparing hand-crafted features and facilitates the use of raw data with minimal pre-processing in anomaly detection tasks. Although autoencoders are simple and effective architectures for outlier detection, the performance gets degraded due to noisy training data.Output of DAD Techniques
A critical aspect for anomaly detection methods is the way in which the anomalies are detected. Generally, the outputs produced by anomaly detection methods are either anomaly score or binary labels.
Anomaly Score:
Anomaly score describes the level of outlierness for each data point. The data instances may be ranked according to anomalous score, and a domain-specific threshold (commonly known as decision score) will be selected by subject matter expert to identify the anomalies. In general, decision scores reveal more information than binary labels. For instance, in Deep SVDD approach the decision score is the measure of the distance of data point from the center of the sphere, the data points which are farther away from the center are considered anomalous.
Labels:
Instead of assigning scores, some techniques may assign a category label as normal or anomalous to each data instance. Unsupervised anomaly detection techniques using autoencoders measure the magnitude of the residual vector (i,e reconstruction error) for obtaining anomaly scores, later on, the reconstruction errors are either ranked or thresholded by domain experts to label data instances.
In this survey paper, we have discussed various research methods in deep learning-based anomaly detection along with its application across various domains. This article discusses the challenges in deep anomaly detection and presents several existing solutions to these challenges. For each category of deep anomaly detection techniques, we present the assumption regarding the notion of normal and anomalous data along with its strength and weakness. The goal of this survey was to investigate and identify the various deep learning models for anomaly detection and evaluate its suitability for a given dataset. When choosing a deep learning model to a particular domain or data, these assumptions can be used as guidelines to assess the effectiveness of the technique in that domain. Deep learning based anomaly detection is still active research, and a possible future work would be to extend and update this survey as more sophisticated techniques are proposed.
Comments