-By Ranjitha Kumar, Department of Computer Science, Stanford University
ABSTRACT
This thesis describes how data-driven approaches to Web design problems can enable useful interactions for designers. It presents three machine learning applications which enable new interaction mechanisms for Web design: rapid retargeting between page designs, scalable design search, and generative probabilistic model induction to support design interactions cast as probabilistic inference. It also presents a scalable architecture for efficient data-mining on Web designs, which supports these three applications.
MACHINE LEARNING FOR WEB DESIGN
The Web provides an enormous repository of design knowledge: every page represents a concrete example of human creativity and aesthetics. Given the ready availability of Web data, how can we leverage it to help designers? This thesis describes three machine learning applications which enable new interaction mechanisms for Web design: rapid retargeting between page designs to automatically transfer the content from one page into the style and layout of another, scalable design search for finding relevant examples during ideation and implementation, and inducing generative probabilistic models from exemplars to support interactions cast as probabilistic inference. It also describes a common infrastructure used in all three applications to support large-scale data-mining and machine learning on Web designs.
Paper contribution
- Data-driven approaches can enable new, principled design interactions that allow people to work with examples in a natural way
Machine learning applications can establish new workflows that allow people to more directly use and learn from the design knowledge on the Web.
2. Leverage structure that is intrinsic to Web designs is key to building more powerful design interactions.
On the Web, every page is associated with a Document Object Model (DOM) tree, which can be used along with render time information to bootstrap a visual information hierarchy for designs. Paper demonstrates that structure is the key to enabling powerful design interactions
3. Understanding the way people think about design can inform the construction of learning algorithms.
A more principled approach is to learn these rules directly from crowdsourced data. The learning applications presented in this thesis train on data collected from people.


RAPID RETARGETING BETWEEN PAGE DESIGNS
People frequently rely on templates when designing Web sites. While templates provide a simple mechanism for rendering content in different layouts, their rigidity often limits customization and yields cookie-cutter designs. This thesis presents Bricolage, a structured prediction algorithm that allows any page on the Web to serve as a design template. The algorithm works by matching visually and semantically similar elements in pages to create coherent mappings between them. Once constructed, these mappings are used to automatically transfer the content from one page into the style and layout of another (Figure 1).
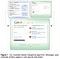

Bricolage uses structured prediction to learn how to transfer content between pages. It trains on a corpus of human-generated mappings, collected using a Web-based crowdsourcing interface. The mapping collector was seeded with 50 popular Web pages that were decomposed into a visual hierarchy by our constraint-based page segmentation algorithm, Bento. In an online study, 39 participants with some Web design experience specified correspondences between page regions and answered free-response questions about their rationale.
To test the effectiveness of Bricolage’s machine learning components, we ran a hold-out test. Bricolage is able to reproduce human mappings with nearly 80% accuracy. Moreover, we show that flexibly preserving structure is essential for predicting human-like mappings. If we don’t account for structure, the accuracy drops to 53%.
Text-based search engines process queries efficiently by computing bag-of-words representations of documents; no such natural vector space describes page designs. Pages are not so obviously fixed-dimensional: they have varying numbers of elements and topology. How do we express topology as a fixed-dimensional vector to afford fast comparisons?
Paper demonstrates that a meaningful search space can be constructed via deep learning, using recent work on recursive neural networks (RNNs) to induce a fixed-dimensional, structurally-sensitive embedding for each element in a page’s visual hierarchy. The RNN framework leverages a set of canonical features to bootstrap a continuous vector space representation for each variable-sized region in a page.


Given this RNN framework, we can turn to people to define what constitutes similarity between pages and page elements. We want to train the parameters of the RNN (e.g. W) so that similar pages and page elements have vector representations that are close together.
By using this representation in a standard cosine similarity framework, we can enable several different types of search queries. Users can select a page, and ask to see similar pages in the database. Since every node in a page has its own embedding, users can also search at multiple scales: searching for similar page elements is the same operation as searching for a similar page (Figure 4).
GENERATIVE PROBABILISTIC MODELS FOR DESIGN
When building sites, skilled designers often rely on formalized knowledge about design patterns, typically encapsulated in books or style guides. Such rules for good design, however, are difficult to enumerate and operationalize. A more attractive proposition is to learn these rules from data.
Machine learning applications trained on page designs require efficient access to the design information from a large corpus of Web pages. To access the design information of a Web page, it is not sufficient to examine its raw HTML: the page must be rendered. Although traditional Web crawlers make it easy to scrape content from pages, acquiring and managing all the resources necessary to preserve a page’s render-time appearance is much more difficult. Furthermore, with the advent of client- and server-side scripting and dynamic HTML, many modern Web pages are mutable and may change between accesses, frustrating algorithms that expect consistent training data.


Using this Bayesian Model Merging technique, we induced a grammar on Web designs from a set of hand-labelled Web page hierarchies. Figure 5 shows a small portion of our corpus of Web pages, as well as a few random derivations from the learned model of page structures.
Conclusion
Paper describes a new kind of Web repository. The repository is populated via a bespoke Web crawler, which requests pages through a caching proxy backed by an SQL database. As a page is crawled, all requested resources are versioned and stored, its DOM tree is processed to produce a static visual hierarchy of the page’s structure, and a set of semantic and vision-based features are calculated on each constituent page component. These structures are then exposed through a RESTful API, allowing fast component-wise queries on features. We have found that this design repository enables the rapid development of a diverse set of machine learning applications that support creative work.
Comments